业务背景
在大型网站中,为了减少DB压力、让数据更精准、速度更快,将读拆分出来采用搜索引擎来为DB分担读的压力,ElasticSearch就是目前市面上比较流行的搜索引擎,他的检索速度奇快、支持各种复杂的全文检索,在各种场景下对比其他的搜索引擎的检索速度都显得尤为出众。这篇就先不介绍ElasticSearch了,后续我会出一个ElasticSearch的教程,目前已经写的查不多了,mq相信大家应该最熟悉就不过多介绍了。
使用搜索引擎,我们需要将DB中的数据同步到搜索引擎中,上次的一个迭代版本中,PD为了保证让用户看见最优质的数据所以讲搜索引擎中的数据进行优化,简称:搜索池。将一些不达标的数据不展示出给用户。搜索将多种类型的数据添加各种进入搜索池的条件,这么添加修改搜索池操作频繁并且如果处理时间过长可能会引发超时等等一些问题,影响了核心业务的操作。所以讲同步搜索池数据的操作采用mq异步执行同步数据任务,这样数据的同步就不会影响核心业务的操作。但是虽然解决了保证核心业务的处理但是有时也会有许多坑,这里小编就分享一次踩坑经历。
问题背景
在批量同步数据的时候,每次执行了一遍删除数据的个数与添加一遍后的个数对不上,例如:一共有20条数据,删除一批数据剩10条,同样的添加了这批数据还剩18条,这2条数据就丢了。这时候就比较苦恼了,检查了业务与另一个线程的业务也没有发现报错或者逻辑出现问题。因为公司原因,这里就用伪代码写:
public Integer 方法名(参数){ //批量修改操作 DAO 参数集合.forEash(s->{ //将跌在变量的id发送mq });} 问题分析
这里是修改完数据后发送mq请求,根据传参的不同添加或者删除 搜索引擎中的数据。按逻辑来说这样子写是没有什么问题的。但是经过层层的调试,终于发现了问题所在。在我们的系统中这个类是被加上事物的,因为是update数据所以这些操作都是会加上事物的。那事物为什么会影响呢?看下图
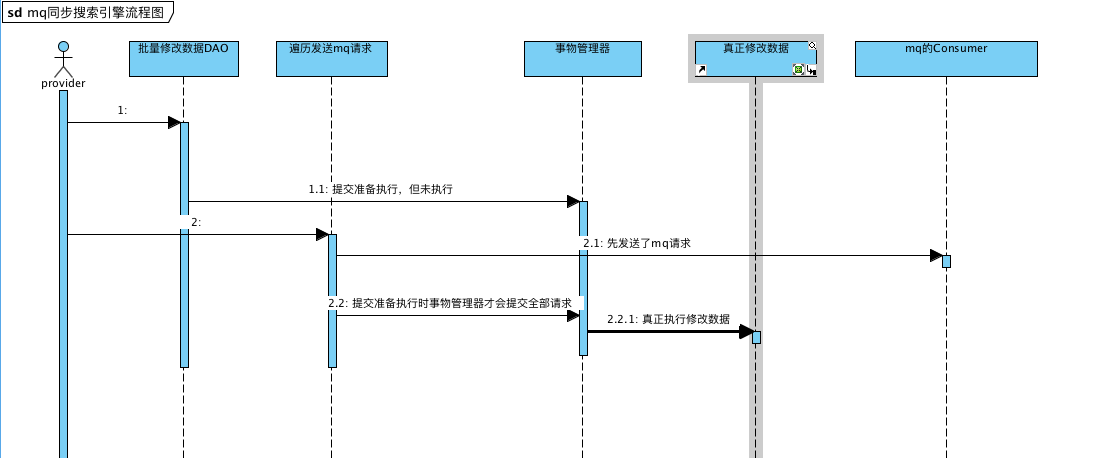
很明显的看到在没有真正修改数据之前先发送了mq请求,而mq拿到请求去查询这些数据的时候这些数据的状态还没有被真正修改。所以先发送mq请求和真正修改数据之间的短时间变差,导致了优先被发送mq请求的前几条数据出现问题。所以在批量发送mq请求的时候一定要注意事物控制的问题,单量操作一般不会出现问题,因为单量的速度是很快的。提醒大家在提高性能的同时,一定要仔细评估方案细节。